The Data Science Lab
Neural Network Back-Propagation Using Python
You don't have to resort to writing C++ to work with popular machine learning libraries such as Microsoft's CNTK and Google's TensorFlow. Instead, we'll use some Python and NumPy to tackle the task of training neural networks.
Over the past year or so, among my colleagues, the use of sophisticated machine learning (ML) libraries, such as Microsoft's CNTK and Google's TensorFlow, has increased greatly. Most of the popular ML libraries are written in C++ for performance reasons, but have a Python API interface. This means that if you want to work with ML, it's becoming increasingly important to have a familiarity with the Python language and with basic neural network concepts.
In this article, I'll explain how to implement the back-propagation (sometimes spelled as one word without the hyphen) neural network training algorithm from scratch, using just Python 3.x and the NumPy (numerical Python) package. After reading this article you should have a solid grasp of back-propagation, as well as knowledge of Python and NumPy techniques that will be useful when working with libraries such as CNTK and TensorFlow.
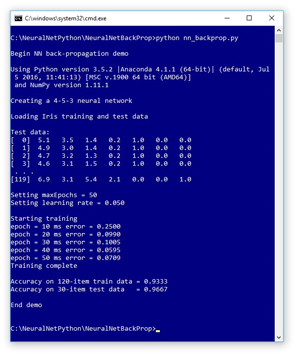
A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo Python program uses back-propagation to create a simple neural network model that can predict the species of an iris flower using the famous Iris Dataset. The demo begins by displaying the versions of Python (3.5.2) and NumPy (1.11.1) used. Although it is possible to install Python and NumPy separately, it’s becoming increasingly common to use an Anaconda distribution (4.1.1) as I did.
 [Click on image for larger view.]
Figure 1. Python Neural Network Back-Propagation Demo
[Click on image for larger view.]
Figure 1. Python Neural Network Back-Propagation Demo
The Iris Dataset has 150 items. Each item has four numeric predictor variables (often called features): sepal length and width, and petal length and width, followed by the species ("setosa," "versicolor" or "virginica"). The demo program uses 1-of-N label encoding, so setosa = (1,0,0) and versicolor = (0,1,0) and virginica = (0,0,1). The goal is to predict species from sepal and petal length and width.
The 150-item dataset has 50 setosa items, followed by 50 versicolor, followed by 50 virginica. Before writing the demo program, I created a 120-item file of training data (using the first 30 of each species) and a 30-item file of test data (the leftover 10 of each species).
The demo program creates a simple neural network with four input nodes (one for each feature), five hidden processing nodes (the number of hidden nodes is a free parameter and must be determined by trial and error), and three output nodes (corresponding to encoded species). The demo loaded the training and test data into two matrices.
The back-propagation algorithm is iterative and you must supply a maximum number of iterations (50 in the demo) and a learning rate (0.050) that controls how much each weight and bias value changes in each iteration. Small learning rate values lead to slow but steady training. Large learning rates lead to quicker training at the risk of overshooting good weight and bias values. The max-iteration and leaning rate are free parameters.
The demo displays the value of the mean squared error, every 10 iterations during training. As you'll see shortly, there are two error types that are commonly used with back-propagation, and the choice of error type affects the back-propagation implementation. After training completed, the demo computed the classification accuracy of the resulting model on the training data (0.9333 = 112 out of 120 correct) and on the test data (0.9667 = 29 out of 30 correct). The classification accuracy on a set of test data is a very rough approximation of the accuracy you'd expect to see on new, previously unseen data.
This article assumes you have a solid knowledge of the neural network input-output mechanism, and intermediate or better programming skill with a C-family language (C#, Python, Java), but doesn’t assume you know much about the back-propagation algorithm. The demo program is too long to present in its entirety in this article, but the complete source code is available in the accompanying file download.
Understanding Back-Propagation
Back-propagation is arguably the single most important algorithm in machine learning. A complete understanding of back-propagation takes a lot of effort. But from a developer's perspective, there are only a few key concepts that are needed to implement back-propagation. In the discussion that follows, for simplicity I leave out many important details, and take many liberties with the underlying mathematics.
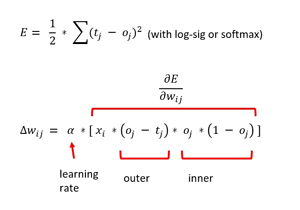
Take a look at the two math equations for back-propagation in Figure 2. The top equation defines a sum of squares error metric and is the starting point for back-propagation. The tj stands for a target value and the oj stands for a computed output value. Suppose a target value is (1, 0, 0) corresponding to setosa. And suppose that for a given set of weight and bias values, and a set of four input values, the computed output values are (0.70, 0.10, 0.20). The squared error is 1/2 * [ (1 - 0.70)^2 + (0 - 0.10)^2 + (0 - 0.20)^2 ] = 1/2 * (0.09 + 0.01 + 0.04) = 0.07. Notice the seemingly arbitrary 1/2 term.
 [Click on image for larger view.]
Figure 2. Back-Propagation Update for Hidden-to-Output Weights
[Click on image for larger view.]
Figure 2. Back-Propagation Update for Hidden-to-Output Weights
The goal of back-propagation training is to minimize the squared error. To do that, the gradient of the error function must be calculated. The gradient is a calculus derivative with a value like +1.23 or -0.33. The sign of the gradient tells you whether to increase or decrease the weights and biases in order to reduce error. The magnitude of the gradient is used, along with the learning rate, to determine how much to increase or decrease the weights and biases.
Using some very clever mathematics, you can compute the gradient. The bottom equation in Figure 2 is the weight update rule for a single output node. The amount to change a particular weight is the learning rate (alpha) times the gradient. The gradient has four terms. The xi is the input associated with the weight that’s being examined. The (oj - tj) is the derivative of the outside part of the error function: the 2 exponent drops to the front, canceling the 1/2 (which is the only reason the 1/2 term is there), then you multiply by the derivative of the inside, which is -1 times the derivative of the function used to compute the output node.
The third and fourth terms of the gradient come from the activation function used for the output nodes. For classification, this is the softmax function. As it turns out, the derivative of an output node oj is, somewhat surprisingly, oj * (1 - oj). To summarize, the back-propagation weight update rule depends on the derivative of the error function and the derivative of the activation function.
There are some important additional details. The squared error term can be defined using (target -output)^2 instead of (output - target)^2 and give the same error because of the squaring operation. But reversing the order will change the sign of the resulting (target - output) term in the gradient. This in turn affects whether you should add the delta-w term or subtract it when you update weights and biases.
OK, so updating the weights and biases for hidden-to-output weights isn't too difficult. But what about the weight update rule for input-to-hidden weights? That equation is more complicated and in my opinion is best understood using code rather than a math equation, as I'll present shortly. The Wikipedia article on back-propagation has a very good derivation of the weight update rule for both output and hidden nodes.
Overall Demo Program Structure
The overall demo program structure is presented in Listing 1. To edit the demo program, I used the simple Notepad++ program. Most of my colleagues prefer using one of the many nice Python editors that are available.
I commented the name of the program and indicated the Python version used. I added four import statements to gain access to the NumPy package's array and matrix data structures, and the math and random modules. The sys module is used only to programmatically display the Python version, and can be omitted in most scenarios.
Listing 1: Overall Program Structure
# nn_backprop.py
# Python 3.x
import numpy as np
import random
import math
import sys
# ------------------------------------
def loadFile(df): . . .
def showVector(v, dec): . . .
def showMatrix(m, dec): . . .
def showMatrixPartial(m, numRows, dec, indices): . . .
# ------------------------------------
class NeuralNetwork: . . .
# ------------------------------------
def main():
print("\nBegin NN back-propagation demo \n")
pv = sys.version
npv = np.version.version
print("Using Python version " + str(pv) +
"\n and NumPy version " + str(npv))
numInput = 4
numHidden = 5
numOutput = 3
print("\nCreating a %d-%d-%d neural network " %
(numInput, numHidden, numOutput) )
nn = NeuralNetwork(numInput, numHidden, numOutput, seed=3)
print("\nLoading Iris training and test data ")
trainDataPath = "irisTrainData.txt"
trainDataMatrix = loadFile(trainDataPath)
print("\nTest data: ")
showMatrixPartial(trainDataMatrix, 4, 1, True)
testDataPath = "irisTestData.txt"
testDataMatrix = loadFile(testDataPath)
maxEpochs = 50
learnRate = 0.05
print("\nSetting maxEpochs = " + str(maxEpochs))
print("Setting learning rate = %0.3f " % learnRate)
print("\nStarting training")
nn.train(trainDataMatrix, maxEpochs, learnRate)
print("Training complete")
accTrain = nn.accuracy(trainDataMatrix)
accTest = nn.accuracy(testDataMatrix)
print("\nAccuracy on 120-item train data = %0.4f " % accTrain)
print("Accuracy on 30-item test data = %0.4f " % accTest)
print("\nEnd demo \n")
if __name__ == "__main__":
main()
# end script
----------------------------------------------------------------------------------
The demo program consists mostly of a program-defined NeuralNetwork class. I created a main function to hold all program control logic. I started by displaying some version information:
def main():
print("\nBegin NN back-propagation demo \n")
pv = sys.version
npv = np.version.version
print("Using Python version " + str(pv) +
"\n and NumPy version " + str(npv))
...
Next, I created the demo neural network, like so:
numInput = 4
numHidden = 5
numOutput = 3
print("\nCreating a %d-%d-%d neural network " %
(numInput, numHidden, numOutput) )
nn = NeuralNetwork(numInput, numHidden, numOutput, seed=3)
The NeuralNetwork constructor accepts a seed value to initialize a class-scope random number generator object. The RNG object is used to initialize all weights and bias values to small random numbers between -0.01 and +0.01 using class method initializeWeights. The RNG object is also used during training to scramble the order in which training items are processed. The seed value of 3 is arbitrary.
The constructor assumes that the tanh function is used for hidden node activation. As you'll see shortly, if you use a different activation function such as logistic sigmoid or rectified linear unit (ReLU), the back-propagation code for updating the hidden node weights and bias values will be affected.
The demo loads training and test data using these statements:
print("\nLoading Iris training and test data ")
trainDataPath = "irisTrainData.txt"
trainDataMatrix = loadFile(trainDataPath)
print("\nTest data: ")
showMatrixPartial(trainDataMatrix, 4, 1, True)
testDataPath = "irisTestData.txt"
testDataMatrix = loadFile(testDataPath)
Helper function loadFile does all the work. The function is hardcoded to assume that the source data is comma-delimited, is ordered with features followed by encoded species, and does not have a header line. Writing code from scratch allows you to be very concise, as opposed to writing general-purpose library code, which requires you to take into account all kinds of scenarios and add huge amounts of error-checking code.
The back-propagation training is invoked like so:
maxEpochs = 50
learnRate = 0.05
print("\nSetting maxEpochs = " + str(maxEpochs))
print("Setting learning rate = %0.3f " % learnRate)
print("\nStarting training")
nn.train(trainDataMatrix, maxEpochs, learnRate)
print("Training complete")
Behind the scenes, method train uses the back-propagation algorithm and displays a progress message with the current mean squared error, every 10 iterations. It's important to monitor progress during neural network training because it's not uncommon for training to stall out completely, and if that happens you don't want to wait for an entire training run to complete.
In non-demo scenarios, the maximum number of training iterations/epochs can be in the thousands, so printing errors every 10 iterations might be too often. You might want to consider passing a parameter to the train method that controls when to print progress messages.
The demo program concludes with these statements:
...
accTrain = nn.accuracy(trainDataMatrix)
accTest = nn.accuracy(testDataMatrix)
print("\nAccuracy on 120-item train data = %0.4f " % accTrain)
print("Accuracy on 30-item test data = %0.4f " % accTest)
print("\nEnd demo \n")
if __name__ == "__main__":
main()
# end script
Notice that during training you’re primarily interested in error, but after training you’re primarily interested in classification accuracy.
The Neural Network Class
The structure of the Python neural network class is presented in Listing 2. Python function and method definitions begin with the def keyword. All class methods and data members have essentially public scope as opposed to languages like Java and C#, which can impose private scope. The built-in __init__ method (with two leading and two trailing underscore characters) can be loosely thought of as a constructor. All class method definitions must include the "self" keyword as the first parameter, except for methods that are decorated with the @staticmethod attribute.