The Data Science Lab
Binary Classification Using PyTorch, Part 1: New Best Practices
Because machine learning with deep neural techniques has advanced quickly, our resident data scientist updates binary classification techniques and best practices based on experience over the past two years.
A binary classification problem is one where the goal is to predict a discrete value where there are just two possibilities. For example, you might want to predict the gender (male or female) of a person based on their age, state where they live, annual income and political leaning (conservative, moderate, liberal).
Previous articles in Visual Studio Magazine have explained binary classification using PyTorch. But machine learning with deep neural techniques has advanced quickly. This article updates binary classification techniques and best practices based on experience over the past two years.
A good way to see where this article is headed is to take a look at the screenshot of a demo program in Figure 1. The demo begins by loading a 200-item file of training data and a 40-item set of test data. Each tab-delimited line represents a person. The fields are gender (male = 0, female = 1), age, state of residence, annual income and politics type. The goal is to predict gender from age, state, income and political leaning.
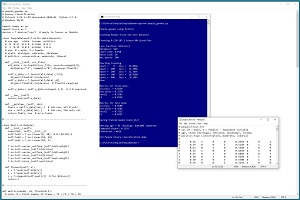 [Click on image for larger view.] Figure 1: Binary Classification Using PyTorch Demo Run
[Click on image for larger view.] Figure 1: Binary Classification Using PyTorch Demo Run
After the training data is loaded into memory, the demo creates an 8-(10-10)-1 neural network. This means there are eight input nodes, two hidden neural layers with 10 nodes each and one output node.
The demo prepares to train the network by setting a batch size of 10, stochastic gradient descent (SGD) optimization with a learning rate of 0.01, and maximum training epochs of 500 passes through the training data. The meaning of these values and how they are determined will be explained shortly.
The demo program monitors training by computing and displaying loss values. The loss values slowly decrease, which indicates that training is probably succeeding. The magnitude of the loss values isn't directly interpretable; the important thing is that the loss decreases.
After 500 training epochs, the demo program computes the accuracy of the trained model on the training data as 82.50 percent (165 out of 200 correct). The model accuracy on the test data is 85.00 percent (34 out of 40 correct). For binary classification models, in addition to accuracy, it's standard practice to compute additional metrics: precision, recall and F1 score.
After evaluating the trained network, the demo saves the trained model to file so that it can be used without having to retrain the network from scratch. There are two main ways to save a PyTorch model. The demo uses the save-state approach.
After saving the model, the demo predicts the gender for a person who is 30 years old, from Oklahoma, who makes $40,000 annually and is politically moderate. The raw prediction is 0.3193. This value is a pseudo-probability where values less than 0.5 indicate class 0 (male) and values greater than 0.5 indicate class 1 (female). Therefore the prediction is male.
This article assumes you have a basic familiarity with Python and intermediate or better experience with a C-family language but does not assume you know much about PyTorch or neural networks. The complete demo program source code and data can be found here.
Installing PyTorch
The demo program was developed on a Windows 10/11 machine using the Anaconda 2020.02 64-bit distribution (which contains Python 3.7.6) and PyTorch version 1.12.1 for CPU. Installing PyTorch is like driving a car -- relatively easy once you know how but difficult if you haven't done it before.
I work at a large tech company, and one of my job responsibilities is to deliver training classes to software engineers and data scientists. By far the biggest hurdle for people who are new to PyTorch is installation.
There are dozens of different ways to install PyTorch on Windows. The configuration I strongly recommend for beginners is to use the Anaconda distribution of Python and install PyTorch using the pip package manager. The Anaconda distribution of Python contains a base Python engine plus over 500 add-in packages that have been tested to be compatible with one another.
After you have a Python distribution installed, you can install PyTorch in several different ways. I recommend using the pip utility, which is installed as part of Anaconda. Briefly, you download a .whl ("wheel") file to your local machine, open a command shell and issue the command "pip install (whl-file-name)."
I have published detailed step-by-step instructions for installing Anaconda Python for Windows 10/11 and detailed instructions for downloading and installing PyTorch 1.12.1 for Python 3.7.6 on a Windows CPU machine.
Preparing the Data
The raw demo data looks like:
F 24 michigan 29500.00 liberal
M 39 oklahoma 51200.00 moderate
F 63 nebraska 75800.00 conservative
M 36 michigan 44500.00 moderate
. . .
There are 240 lines of data. Each line represents a person. The five fields are sex (M, F), age, state of residence (Michigan, Nebraska, Oklahoma), annual income and politics type (conservative, moderate, liberal). The data is artificial. The raw data was split into a 200-item set for training and a 40-item set for testing.
The raw data must be encoded and normalized. The result is:
1 0.24 1 0 0 0.2950 0 0 1
0 0.39 0 0 1 0.5120 0 1 0
1 0.63 0 1 0 0.7580 1 0 0
0 0.36 1 0 0 0.4450 0 1 0
. . .
The variable to predict (often called the class or the label) is gender, which has possible values of male or female. For PyTorch binary classification, you should encode the variable to predict using 0-1 encoding. The demo sets male = 0, female = 1. The order of the encoding is arbitrary.
Because neural networks only understand numbers, the state and political leaning predictor values (often called features in neural network terminology) must be encoded. The state values are one-hot encoded as Michigan = (1 0 0), Nebraska = (0 1 0) and Oklahoma = (0 0 1). The order of the encoding is arbitrary. If the state variable had four possible values, then the encodings would be (1 0 0 0), (0 1 0 0) and so on. The political leaning values are one-hot encoded as conservative = (1 0 0), moderate = (0 1 0) and liberal = (0 0 1).
The demo data normalizes the numeric age and annual income values. The age values are divided by 100; for example, age = 24 is normalized to age = 0.24. The income values are divided by 100,000; for example, income = $55,000.00 is normalized to 0.5500. The resulting normalized age and income values are all between 0.0 and 1.0.
The technique of normalizing numeric data by dividing by a constant does not have a standard name. Two other normalization techniques are called min-max normalization and z-score normalization. I recommend using the divide-by-constant technique whenever possible. There is convincing (but currently unpublished) research that indicates divide-by-constant normalization usually gives better results than min-max normalization or z-score normalization. The topic is quite complex. For details, see "Why I Don't Use Min-Max or Z-Score Normalization For Neural Networks."
The demo data does not have any binary predictor variables such as "employed" with possible values yes or no. For binary predictor variables I recommend using minus-one-plus-one encoding rather than 0-1 encoding. In theory both encoding schemes work for binary predictor variables, but in practice minus-one-plus-one encoding often produces a better model. For an explanation, see "Should You Encode Neural Network Binary Predictors as 0 and 1, or as -1 and +1?"
The demo preprocesses the raw data by normalizing numeric values and encoding categorical values. It is possible to normalize and encode training and test data on the fly, but preprocessing is usually a simpler approach.
Overall Program Structure
The overall structure of the demo program is presented in Listing 1. The demo program is named people_gender.py. The program imports the NumPy (numerical Python) library and assigns it an alias of np. The program imports PyTorch and assigns it an alias of T. Most PyTorch programs do not use the T alias but my work colleagues and I often do so to save space. The demo program indents using two spaces rather than the more common four spaces, again to save space.
Listing 1: Overall Program Structure
# people_gender.py
# binary classification
# PyTorch 1.12.1-CPU Anaconda3-2020.02 Python 3.7.6
# Windows 10/11
import numpy as np
import torch as T
device = T.device('cpu')
class PeopleDataset(T.utils.data.Dataset): . . .
class Net(T.nn.Module): . . .
def metrics(model, ds, thresh=0.5): . . .
def main():
# 0. get started
print("People gender using PyTorch ")
T.manual_seed(1)
np.random.seed(1)
# 1. create Dataset objects
# 2. create network
# 3. train model
# 4. evaluate model accuracy
# 5. save model (state_dict approach)
# 6. make a prediction
print("End People binary classification demo ")
if __name__ == "__main__":
main()
The global device is set to "cpu." If you are working with a machine that has a GPU processor, the device string is "cuda." Most of my colleagues and I develop neural networks on a local CPU machine, then if necessary (huge amount of training data or huge neural network), push the program to a GPU machine and train it there.
The demo has a program-defined PeopleDataset class that stores training and test data. The data in a Dataset object can be served up in batches for training by using the built-in DataLoader object. It is possible to use training and test data directly instead of using a Dataset, but such problem scenarios are rare and you should use a Dataset for most problems.
The binary neural network classifier is implemented in a program-defined Net class. The Net class inherits from the built-in torch.nn.Module class, which supplies most of the neural network functionality. Instead of using a class to define a PyTorch neural network, it is possible to create a neural network directly using the torch.nn.Sequential class. Using Sequential is simpler but less flexible than using a program-defined class. The fact that there are two completely different ways to define a PyTorch neural network can be confusing for beginners.
In a neural network binary classification problem, you must implement a program-defined function to compute classification accuracy of the trained model. The demo program defines a metrics() function that accepts a network and a Dataset object.
All of the demo program control logic is contained in a program-defined main() function. The demo program begins by setting the seed values for the NumPy random number generator and the PyTorch generator. Setting seed values is helpful so that demo runs are mostly reproducible. However, when working with complex neural networks such as Transformer networks, exact reproducibility cannot always be guaranteed because of separate threads of execution.
The Dataset Definition
The demo Dataset definition is presented in Listing 2. A Dataset inherits from the torch.utils.data.Dataset class, and you must implement three methods:
- __init__(), which loads the data from file into memory as PyTorch tensors
- __len__(), which tells the DataLoader object that uses the Dataset how many items there so that the DataLoader knows when all items have been processed during training
- __getitem__(), which returns a single data item, rather than a batch of items as you might have expected
Listing 2: Dataset Definition
class PeopleDataset(T.utils.data.Dataset):
# like 0 0.27 0 1 0 0.7610 1 0 0
def __init__(self, src_file):
all_data = np.loadtxt(src_file, usecols=range(0,9),
delimiter="\t", comments="#", dtype=np.float32)
self.x_data = T.tensor(all_data[:,1:9],
dtype=T.float32).to(device)
self.y_data = T.tensor(all_data[:,0],
dtype=T.float32).to(device) # float32 required
self.y_data = self.y_data.reshape(-1,1) # 2-D required
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
feats = self.x_data[idx,:] # idx row, all 8 cols
sex = self.y_data[idx,:] # idx row, the only col
return feats, sex # as a Tuple
Defining a PyTorch Dataset is not trivial. You must define a custom Dataset for each problem/data scenario. The __init__() method accepts a src_file parameter that tells the Dataset where the file of training data is located. The entire file is read into memory as a NumPy two-dimensional array using the NumPy loadtxt() function. Commonly used alternatives include the NumPy genfromtxt() function and the Pandas read_csv() function.
The call to loadtxt() specifies argument comments="#" to indicate that lines beginning with "#" are comments and should be ignored. The "#" character is the default for comments and so the argument could have been omitted.
The syntax all_xy[:,1:9] means all rows in matrix all_xy, columns [1] to [8] inclusive. The syntax all_xy[:,0] means all rows, just column [0]. The data is read in as type float32, which is the default data type for PyTorch predictor values.